von Petra Maier
Das Projekt ‚Textdatenbank und Wörterbuch des Klassischen Maya‘ (TWKM) will alle überlieferten Inschriftenträger des Klassischen Maya, d. h. aus der Zeit vor der Eroberung durch die Spanier um 1500 n. Chr., vollständig entziffern und mittels eines Metadatenkonzepts dokumentieren. Auf dieser Datengrundlage soll die systematische Analyse der Struktur der Sprache und des Schriftsystems des Klassischen Maya erfolgen.
Das Projekt, das im Januar 2014 an der Universität Bonn startete und durch die Nordrhein-Westfälische Akademie der Wissenschaften und Künste geförderte wurde, erfolgte in Kooperation mit der Niedersächsischen Staats- und Universitätsbibliothek Göttingen, welche die technische Umsetzung in der Virtuellen Forschungsumgebung TextGrid betreute. Das Projektteam setzte sich aus Fachwissenschaftlern für Altamerikanistik der Universität Bonn sowie aus Informationswissenschaftlern, die für die technische Infrastruktur zuständig waren, zusammen; die Kommunikation erfolgte in der Regel durch regelmäßige Projekttreffen, Telefonate und über ein Projekt-Wiki.
Im Rahmen eines Praxisprojekts des MALIS-Studiengangs der FH Köln im Sommersemester 2014 wurde unter der Betreuung von Prof. Dr. Heike Neuroth für das TWKM-Projekt ein Metadatenschema für die Erfassung der Maya-Texte erstellt, das in das Gesamtmetadatenkonzept eingebunden ist. Wie im Projektantrag festgelegt wurde hierfür die Auszeichnungssprache der Text Encoding Initiative (TEI) verwendet. Dieses Metadatenschema diente als Grundlage, die im weiteren Verlauf des TWKM-Projektes ergänzt und angepasst wurde.
TEI wird in zahlreichen geisteswissenschaftlichen Projekten für die digitale Erschließung von Texten eingesetzt und hat sich als Standard etabliert. Das Format zeichnet sich durch eine hohe Flexibilität aus, die eine Anpassung an projektspezifische Anforderungen ermöglicht. Da TEI eine große Anzahl an Elementen anbietet, müssen für die Erfassung der Inschriftentexte die relevanten Elemente ausgewählt werden. Speziell für die strukturierte Erfassung epigrafischen Quellmaterials wurden aus den TEI-Richtlinien die sogenannten EpiDoc-Empfehlungen erarbeitet. Für das Metadatenschema wurden sowohl Richtlinien der TEI als auch von EpiDoc herangezogen. Die Richtlinien beider Gemeinschaften sind nach bestimmten Themenfeldern untergliedert: TEI überwiegend nach Textgattungen, EpiDoc nach epigrafischen Quellmaterial bzw. Objekten. Für einen ersten Überblick über die Elemente wurden hierin die Einzelbereiche identifiziert, die für die Erfassung der Maya-Inschriften infrage kommen könnten. Dadurch wurde eine überschaubare Auswahl an Elementen für die Einarbeitung in das TEI-Format getroffen. Im nächsten Schritt wurden die Anforderungen der Wissenschaftler formuliert, die sich aus den Zielen des TWKM-Projektes und in den Gesprächen ergaben. Anhand zur Verfügung gestellter Inschriftenbeispiele erfolgte der Entwurf eines Schemas, das die Anforderungen der Wissenschaftler erfüllte.
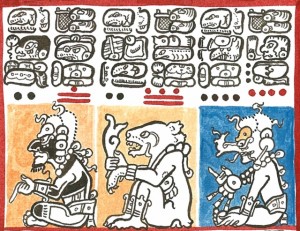
Auch wenn TEI in vielen Projekten der sogenannten ‚Digital Humanities‘ eingesetzt wird, stellen die Maya-Inschriften eine sehr spezielle Schriftform dar: Die Hieroglyphen selbst bestehen aus verschiedenen Schriftzeichen, den Logogrammen und den Silbenzeichen (vgl. Abb. 1).
(Quelle: Sven Gronemeyer: Das Schriftsystem der Maya)
Die Formen der Inschriften variieren stark. Da die genaue Position und Anordnung der einzelnen Zeichen für die systematische Erforschung der Maya-Sprache sehr wichtig sind, ist eine sorgfältige und umfassende Auszeichnung der Inschrift durch TEI notwendig. Um Lösungen für die Umsetzung dieser Ansprüche zu finden, konnten oftmals für das TEI-Metadatenschema des TWKM-Projekts die Beispiele und Ansätze von EpiDoc genutzt werden; insbesondere in den Bereichen, in denen die TEI-Richtlinien nicht für die Beschreibung von Inschriften ausreichen oder die Attribute keine tiefe Spezifizierung zulassen.
Für die Erarbeitung des Metadatenschemas wurden die Texte in verschiedene Abschnitte gegliedert. Zunächst wurde das Gesamtobjekt betrachtet: Auf welcher Seite, an welcher Stelle befinden sich die Inschriftentexte?

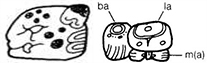
Anschließend wurde der Text einer Objektseite beschrieben (inscription), um zu den einzelnen Textabschnitten und deren Struktur überzugehen (textDivision). Darauf folgend wurden die einzelnen Hieroglyphenblöcke (block) mittels der Metadaten dargestellt und abschließend die einzelnen Zeichen (sign), die einen Hieroglyphenblock bilden (vgl. Abb. 2).

Farbige Bereiche, größer dargestellte Hieroglyphenblöcke sowie Abbildungen mussten ebenfalls ausgezeichnet werden können. Alle Textvarianten und Erscheinungsformen mussten berücksichtigt werden. In der Erarbeitung der Datengrundlagen ergaben sich einige Problemstellen, wie etwa die Darstellung der Datumsangaben oder die Umsetzung nicht fertiggestellter Hieroglyphen, für die zum Abschluss des Teilprojekts noch keine Lösungen erarbeitet wurden.
Um die Anforderungen der Forschung erfüllen zu können, war der regelmäßige Austausch mit den Fachwissenschaftlern die wichtigste Grundlage für die Erstellung eines solchen Metadatenkonzepts. In der engen Zusammenarbeit wurden frühzeitig Probleme erörtert und dadurch notwendige Anpassungen umgesetzt.
Die Erarbeitung des Metadatenkonzepts insgesamt zeigte, dass dieser Bereich große Übereinstimmungen mit der bibliothekarischen Erschließung aufweist: Die Ansetzung normierter Daten für die Namen, das Erstellung kontrollierter Vokabulare und das Erkennen von gemeinsamen Strukturen innerhalb der Daten sind aus der Formal- und Sacherschließung sowie der Ansetzung von Normdaten in Wissenschaftlichen Bibliotheken zu finden – auch wenn die Auszeichnungssprachen für das TWKM-Projekt in Wissenschaftlichen Universalbibliotheken vermutlich kaum eine Rolle spielen.
Ein Blick über den Tellerrand lohnt sich auch für Bibliothekare, da sie durch ihre Expertise Forschungsvorhaben aus dem Bereich der sogenannten Digital Humanities sinnvoll unterstützen könnten.
Publikation:
Petra Maier: “Die Erstellung eines TEI-Metadatenschemas für die Auszeichnung von Texten des Klassischen Maya” DARIAH-DE Working Papers Nr. 8. Göttingen: DARIAH-DE, 2015 URN: http://nbn-resolving.de/urn:nbn:de:gbv:7-dariah-2015-1-6